Problem z połączeniem HTTP/HTTPS w iDRAC9
Wstęp
Wersja firmware 5.10.00.00 dla iDRAC9 przyniosła istotne zmiany w obsłudze protokołów HTTP i HTTPS. Niestety, u części administratorów aktualizacja ta spowodowała niespodziewane błędy połączenia przez FQDN. W tym artykule przedstawiamy, na czym polega problem oraz jak go skutecznie rozwiązać.
Opis problemu technicznego
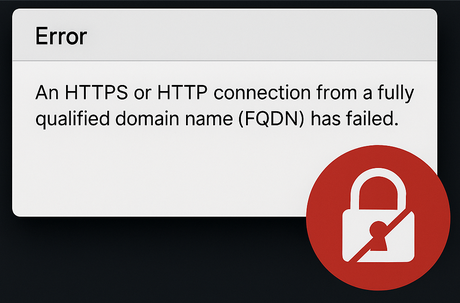
Po zainstalowaniu firmware w wersji 5.10.00.00 w iDRAC9, wielu użytkowników zauważyło, że nie mogą już łączyć się z interfejsem iDRAC używając pełnej nazwy domenowej (FQDN) przez protokoły HTTP lub HTTPS.
Objawy
- Brak dostępu do iDRAC przez FQDN (np.
https://idrac.serwer.local) - Połączenia przez adres IP działają poprawnie
- W logach brak szczegółowych komunikatów o błędach
Przyczyna
Dell wprowadził aktualizację, która modyfikuje sposób, w jaki iDRAC obsługuje nagłówki żądań HTTP/HTTPS przy użyciu FQDN. Wymagany jest teraz zgodny nagłówek Host zgodny z nazwą DNS, a nie wszystkie konfiguracje lokalne to zapewniają.
Rozwiązanie krok po kroku
Poniżej znajdziesz sposób rozwiązania problemu zgodnie z zaleceniami firmy Dell:
- Zaloguj się do iDRAC używając adresu IP (np.
https://192.168.0.100) - Przejdź do sekcji: Configuration > Network > Services
- W sekcji Web Server, znajdź opcję Enable HTTP host header validation
- Odznacz tę opcję
- Kliknij Apply i zrestartuj interfejs iDRAC (lub wykonaj pełny reboot serwera, jeśli wymagane)
- Po restarcie, przetestuj połączenie przez FQDN
Dodatkowe porady
- Jeżeli masz wiele serwerów Dell z iDRAC9, warto zautomatyzować tę zmianę poprzez Redfish API lub RACADM.
- Upewnij się, że wpisy DNS (zarówno A jak i PTR) dla hosta iDRAC są poprawne.
- Rozważ aktualizację do nowszej wersji firmware, jeśli jest dostępna – może zawierać poprawki rozszerzające kompatybilność.
Podsumowanie
Problem z połączeniem HTTP/HTTPS przez FQDN w iDRAC9 firmware 5.10.00.00 wynika z wprowadzonego wymogu walidacji nagłówka Host. Na szczęście, jego wyłączenie w panelu iDRAC pozwala przywrócić prawidłowe działanie. Zalecamy również monitorowanie aktualizacji iDRAC oraz regularne przeglądanie dokumentacji producenta.
Powiązane artykuły
- Jak korzystać z funkcji iDRAC Direct na serwerach Dell PowerEdge
- Błąd MEM7114 w serwerach Dell – przyczyny i skuteczne rozwiązania
GR
Tagi: Dell, iDrac, serwer
 Czym jest błąd MEM7114?
Czym jest błąd MEM7114?